Artificial Anime Character Design: An Application of Generative Adversarial Networks (GANs)

This repository contains implementations of Generative Adversarial Networks (GANs) to design and generate new face images of anime characters. A few improvement techniques were implemented to enhance the performance of the Deep Covolutional GANs (DCGANs) as well as the quality of the output. Also included is an implementation of Least Squares GAN (LSGAN) and NVIDIA’s open source StyleGAN. StyleGAN and StyleGAN2 are new state-of-the-art GAN architectures developed by a team from NVIDIA. These architectures address many of the shortcomings of previous GAN implementations and dramatically increase image quality. This work was done in collaboration with Riley Xu and Tianhao Lu.
Introduction
Generative Adversarial Network (GAN) is a framework for deep learning models to generate superficial data mimicking a training distribution invented by Ian Goodfellow. Facebook’s AI research director Yann LeCun called adversarial training “the most interesting idea in the last 10 years of ML”. GANs have been successfully applied to many image categories, including objects as complicated as human faces, such as This Person Does Not Exist. There are many other attempts to apply GANs on paintings, objects, and even Pokemon. In this work, we train and generate images of character faces from Japanese anime.
Anime is an incredibly popular media format around the world. However, coming up with new character designs takes tremendous effort and skill. GANs offer the opportunity to create new and custom designs without extensive input from a professional. This may help anime studios dramatically shorten development times, provide inspiration to professional and hobbyist character designers, and with sufficient progress may even be able to take over some aspects of the animation.
Related Work
There exist few attempts applying the GAN model to the problem of generating facial images of anime characters. DRAGAN gives a promising result (Jin, 2017); however, other attempts tend to be limited to blog posts and personal github repos, and the methodology and data samples are not well described by these sources. Moreover, the results of these projects are frequently defective, with effects such as asymmetric facial features and having large swaths that make them look like water-color paintings. Most disappointingly, these authors only generated female character faces.
In this work, we seek to improve in the generation of anime character faces. In the following sections, we first describe the data set that we use. Then, we detail three GAN model architectures and show the results. Finally, we compare and quantify the differences between the architectures.
Dataset
Previous works mentioned above have datasets that suffer from high variance and noise, leading to results that were not too promising. Our goal for the data preparation is to find a clean, high-quality dataset and preprocess it in such a way that it can be used seamlessly with PyTorch.
Our dataset consists of 21551 unlabeled anime faces obtained from Kaggle. This is a cleaner version of a dataset originally on Github where the images are fetched from Getchu and then cropped using the anime face detection algorithm (Nagadomi, 2011). The images are generally high-quality, but a few suffer from bad crops. Almost all images have white or otherwise minimal background. The range in art styles, pose, expressions, and hair is sufficiently variant. Notably, this data set does contain male characters, albeit at a smaller proportion, and our networks are trained to generate male faces unlike previous works.
We transformed and loaded the dataset using Pytorch’s ImageFolder and DataLoader classes. We removed as many of the bad samples as possible, mainly poor crops. Additionally, all images are resized to 64x64 for further convenience.

Generative Adversarial Network
GAN uses a generator network $G$ to generate fake samples by mapping a latent space vector $z$ sampled from a normal distribution into a sample $G(z)$. GAN uses a min-max game where discriminator network $D$ tries to maximize its accuracy in classifying real and fake data and $G$ tries to minimize the probability that $D$ will predict its outputs are fake (Goodfellow, 2014). The objective can be formally expressed as:
$$\underset{\scriptsize G}{\text{\scriptsize min}} \underset{\scriptsize D}{\text{\scriptsize max}}V(D,G) = \mathbb{E}_x[\log D(x)]\space+\space\mathbb{E}_z[\log(1-D(G(z)))]$$
The generator and discriminator train off of each other, enabling a GAN to learn unsupervised. In general, the training of a GAN occurs as below:
-
1 - Create a standard normally distributed vector $z$, with arbitrary feature length.
-
2 - Zero out gradient for $G$, generate fake image, and calculate $L_G$, where: $$L_G = \frac{1}{n} \sum_{i=0}^{n} L_{CE}(D(G(z)), 1)$$
-
3 - Backpropogate $L_G$ and step up the optimizer
-
4 - Zero out gradient for $D$ and calculate $L_D$, where: $$L_D = \frac{1}{2n} \sum_{i=0}^{n} L_{CE}(D(X_i), 1) + L_{CE}(D(G(z)), 0)$$
-
5 - Backpropogate $L_D$ and step up optimizer
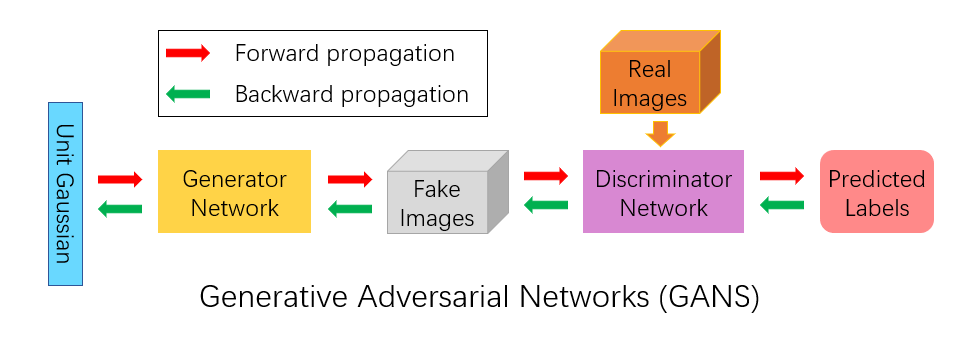
While all GANs have the same basic structure detailed above, there exist many subtleties that result in very different implementations. We explore three implementations: Deep Convolutional, Least Squares, and StyleGAN.
Deep Convolutional GAN (DCGAN)
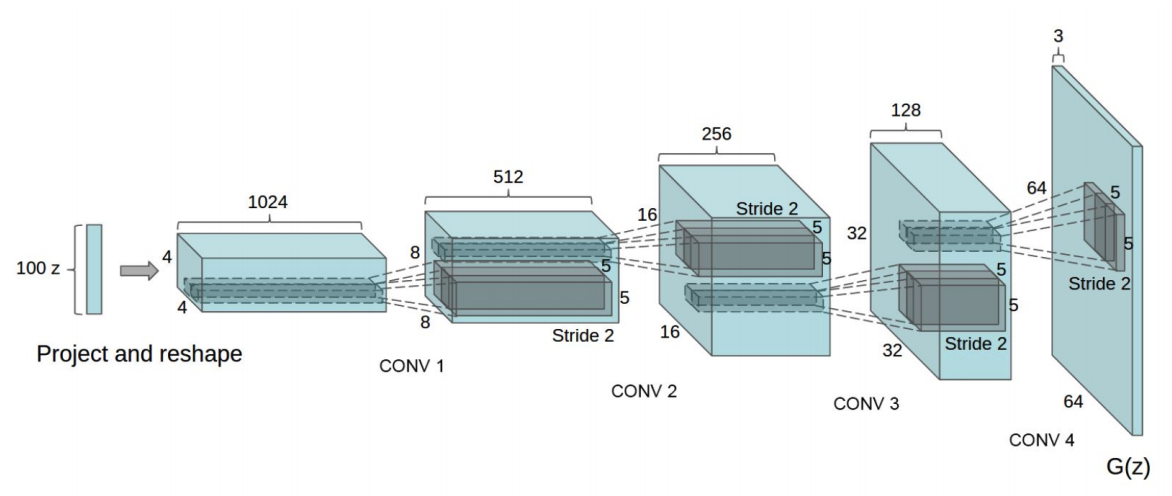
Our base model architecture is inspired by Deep Convolutional GAN (DCGAN) (Radford, 2015). The discriminator is made up of strided convolution layers, 2d batch norm layers, LeakyReLUs, and outputs the final probability through a Sigmoid activation function. The generator consists of a series of strided two dimensional convolutional transpose layers, each followed by a 2d batch norm layer and a ReLU activation. The outputs go through a tanh function.
Training and Hyperparameter Tuning
The figures below show $L_G$ and $L_D$ throughout our training:
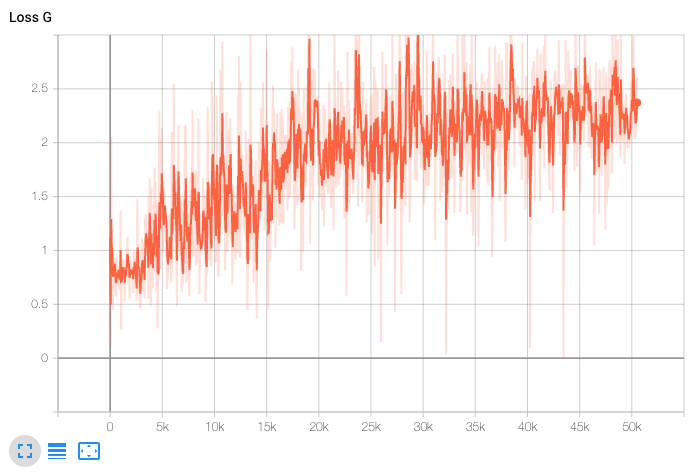
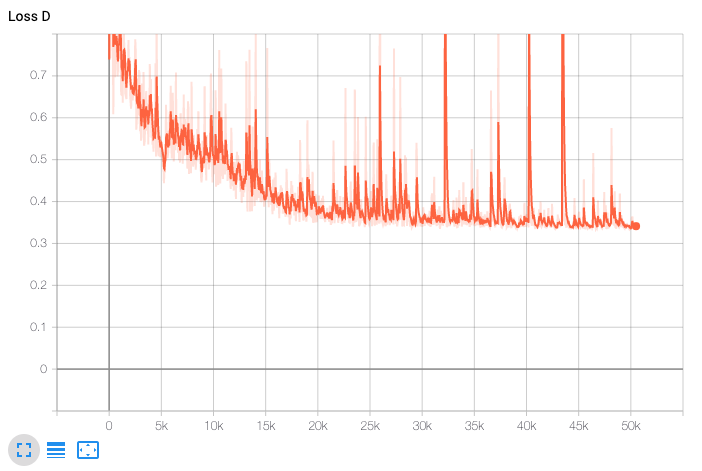
Some things we watched out for during training:
-
1 - We want to prevent the $L_D$ from going to 0 (this represents a failure mode of training).
-
2 - Both $L_D$ and $L_G$ should not decrease monotonically (they should oscillate around a certain loss), with $L_G$ increasing as a whole and $L_D$ decreasing as a whole.
-
3 - Display sample generated images every a certain number of iterations to watch for mode collapse.
We used a batch size of 64 and a feature length of 100 for vector $z$. For both the $G$ and $D$, we use Adam optimizer because it combines the best properties of the AdaGrad and RMSProp algorithms, which can handle sparse gradients on noisy problems. Since $D$ learns much faster than $G$, we set the learning rate for optimizer for $G$ at 0.0005 and optimizer for $D$ at 0.0001. Additionally, we used fuzzy labels - instead of a hard 0 or 1 as labels for the discriminator, we set them to 0.1 and 0.9 to make the discriminator weaker.

Results
Uncurated sample images from our DCGAN model are shown in the figure below. The model was trained on 150 epochs. We find these results quite promising, because most of the generated images are convincing. However, some mistakes are made by the model, such as twisted and broken faces, asymmetric eyes, and non-uniformity in hair. The flaws urge us to try new models.

Least Squares GAN (LSGAN)
A large problem with DCGAN is that it can suffer from vanishing gradients. A variation called Least Squares GAN (LSGAN) attempts to combat the vanishing gradients by using a loss function that provides smooth and non-saturating gradient in discriminator $D$ (Mao, 2016). Formally, the objective functions can be expressed as such:
$$\underset{D}{\text{min}}V_{LS}(D) = \frac{1}{2}\mathbb{E}_{x}[(D(x) - 1)^2] + \frac{1}{2}\mathbb{E}_{z}[(D(G(z)))^2]$$
$$\underset{G}{\text{min}}V_{LS}(G) = \frac{1}{2} \mathbb{E}_{z}[(D(G(z)) - 1)^2]$$
Training and Hyperparameter Tuning
The model architecture we used for LSGAN is exactly the same as that of DCGAN, with a few minor changes. First, we removed the sigmoid activation function at the end of $D$. Moreover, we adjusted the $L_G$ and $L_D$ functions to follow the objective functions described above. We also use the same hyperparameters as we did for DCGAN.
Results
Uncurated samples are shown in the figure below, trained on 150 epochs. As expected, LSGAN performs more stable during the learning process. Unfortunately, our generated samples appear to have more artifacts and less variation.

StyleGAN
StyleGAN and StyleGAN2 are new state-of-the-art GAN architectures developed by a team from NVIDIA (Karras, 2020). These architectures address many of the shortcomings of previous GAN implementations and dramatically increase image quality.
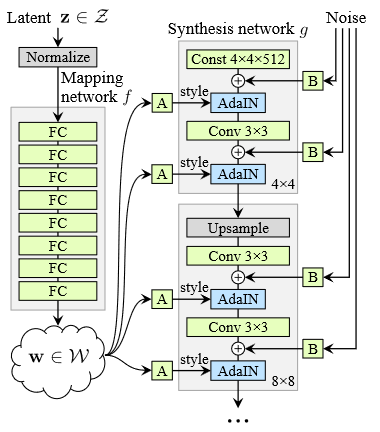
StyleGAN uses a progressive architecture. Both the generator and discriminator are first trained only on 4x4 pixel images. After sufficient progress, a new layer block is added to both networks to handle 8x8 images. This doubling procedure continues until reaching the desired image size. This progression allows the generator to learn fine features after already having learned coarse features, significantly easing the training.
Another key innovation is the adoption of techniques from style-transfer learning. Instead of inputting the latent vector directly into the first layer of the convolution, there is a separate mapping network that processes the latent vector into an intermediate latent vector. This is then transformed into a style vector $y_i$, via a learned affine transformation, and fed into the synthesis network between each convolution layer. The style transfer is done via adaptive instance normalization (AdaIN):
$$\text{AdaIN}(x, y_i) = y_{i,s} \frac{x - \bar x}{\sigma(x)} + y_{i,b}$$
Above, $y_i = (y_{i,s}, y_{i,b})$ is the style scale and bias in layer $i$, and $x$ is the input activations from the previous layer.
Results
Using a baseline StyleGAN architecture implemented in PyTorch, we achieved remarkable results after 150 epochs of training. Uncurated sample fakes are shown in the figure below. Artifacts rarely appear, and there is huge variation between samples. By eye we are generally unable to distinguish fake from real images.

Quantifying Results
A common metric to quantify the quality of generated images is the Frechet Inception Distance (FID) (Heusel, 2017). FID is an improvement on the Inception Score (Salimans, 2016) and calculates the similarity between two sets of images, unsupervised. As with Inception Score, FID uses the Inception V3 model, a trained classifier on 1000 objects. However, instead of using the output of the Inception V3 model, FID calculates the Frechet distance of the activations in the coding layer. Because classifier networks tend to learn general features, using the coding layer generalizes the Inception Score to arbitrary image sets with good effect.
We calculated the FIDs comparing generated images from each GAN implementation with the original data set. All implementations were trained on 150 epochs. The results are summarized in the table below; note lower FID scores are better. StyleGAN outperformed DCGAN, while LSGAN seriously underperformed. These observations corroborate our qualitative assessments.

Conclusion
In this work, we explored the artificial creation of the anime characters using GANs. By extracting a clean data set and introducing several practical training strategies, we showed that DCGANs can produce convincing fakes. We then implemented StyleGAN, a major improvement on DCGAN both qualitatively and by FID score. Additionally, StyleGAN can be trivially used to mix styles.
With the power of style mixing, many possibilities exist for future developments. Assuming a data set with labels, the model can learn to generate specific features on-demand, such as hair color or pose. Other directions are to improve the final resolution of generated images, or to generate full-body designs.
GANs are a very new innovation, but it will not be long before they become used in mainstream disciplines. This work has demonstrated that GANs can be readily applied to the anime industry, allowing for streamlined design of new characters.
Acknowledgement
We acknowledge NVIDIA for their open-source StyleGAN implementation, Google for supplying the Inception V3 model, and Github user mseitzer for creating a PyTorch implementation of the FID calculation.
References
Please see our paper for full list of references.